
使用freemarker可以方便的生成doc或者docx文档,但是在代码开始之前需要准备一些东西,生成doc和docx略有不同。
首先我们准备一个WORD文档,这里我的名字是4spaces.docx,内容如下:
生成doc文档和docx文档所需的准备文件如下:
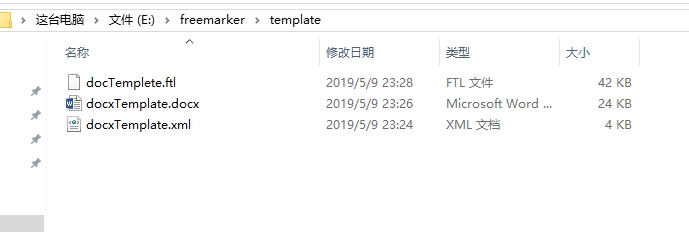
我的目录结构如下:
导出doc文档
1.将4spaces.docx另存为WORD 2003 XML文档(*.xml)
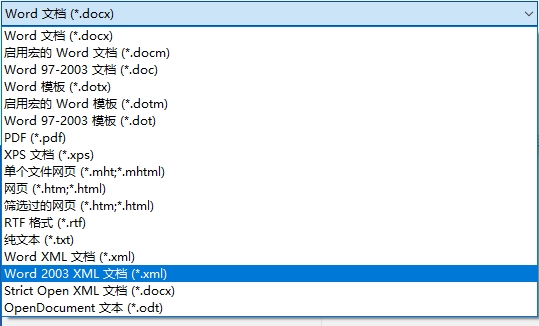
我这里命名为docTemplete.xml,位置放在E:\freemarker\template\目录下。
2.打开docTemplete.xml
这里我要将四个空格-https://www.4spaces.org的内容,通过Java代码动态传入,搜索文件,将四个空格-https://www.4spaces.org用${name}替换,用来占位。
3.重命名
将docTemplete.xml重命名为docTemplete.ftl。
至此,导出doc文件的准备工作完成,下面就是代码。
/**
* 生成doc文件
*
* @param ftlFileName 模板ftl文件的名称
* @param params 动态传入的数据参数
* @param outFilePath 生成的最终doc文件的保存完整路径
*/
public void ftlToDoc(String ftlFileName, Map params, String outFilePath) {
try {
/** 加载模板文件 **/
Template template = configuration.getTemplate(ftlFileName);
/** 指定输出word文件的路径 **/
File docFile = new File(outFilePath);
FileOutputStream fos = new FileOutputStream(docFile);
Writer bufferedWriter = new BufferedWriter(new OutputStreamWriter(fos, "utf-8"), 10240);
template.process(params, bufferedWriter);
if (bufferedWriter != null) {
bufferedWriter.close();
}
} catch (TemplateException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
导出docx文档
1.准备docx格式的模板
将开始准备4spaces.docx文件,复制一份,放到E:\freemarker\template\下,命名为docxTemplate.docx;
2.准备xml格式的模板
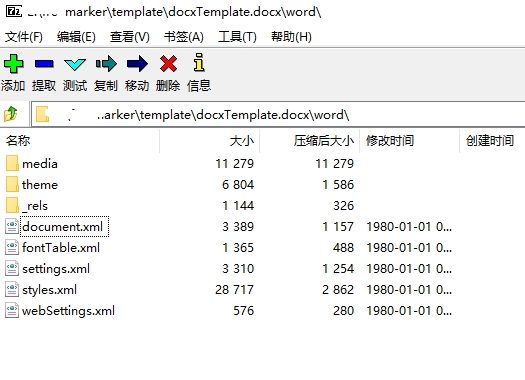
用解压软件打开docxTemplate.docx,将word目录下的document.xml复制一份出来,命名为docxTemplate.xml,放在E:\freemarker\template\目录下,用文本编辑器打开docxTemplate.xml,搜索四个空格,替换为${name},占位符。
3.创建一个临时目录
我的这里是E:\freemarker\temp\,位置可以随意,生成docx的过程中存放临时填充数据的temp.xml(当然你也可以用其他的文件名,代码里有体现),文件名随意,但临时目录必须真实存在,不然会报错。
至此,导出docx文件的准备工作完成,下面就是代码。
/**
* 生成docx文件
*
* @param docxTemplate docx的模板docx文件路径
* @param docxXmlTemplate docx的模板xml文件名称
* @param tempDocxXmlPath docx的临时xml文件(docx的模板xml文件填充完数据生成的临时文件)
* @param params 填充到docx的临时xml文件中的数据
* @param toFilePath 最终输出的docx文件路径
*/
public void xmlToDocx(String docxTemplate, String docxXmlTemplate, String tempDocxXmlPath, Map params, String toFilePath) {
try {
Template template = configuration.getTemplate(docxXmlTemplate);
Writer fileWriter = new FileWriter(new File(tempDocxXmlPath));
template.process(params, fileWriter);
if (fileWriter != null) {
fileWriter.close();
}
File docxFile = new File(docxTemplate);
ZipFile zipFile = new ZipFile(docxFile);
Enumeration<? extends ZipEntry> zipEntrys = zipFile.entries();
ZipOutputStream zipout = new ZipOutputStream(new FileOutputStream(toFilePath));
int len = -1;
byte[] buffer = new byte[1024];
while (zipEntrys.hasMoreElements()) {
ZipEntry next = zipEntrys.nextElement();
InputStream is = zipFile.getInputStream(next);
//把输入流的文件传到输出流中 如果是word/document.xml由我们输入
zipout.putNextEntry(new ZipEntry(next.toString()));
if ("word/document.xml".equals(next.toString())) {
//InputStream in = new FileInputStream(new File(XmlToDocx.class.getClassLoader().getResource("").toURI().getPath()+"template/test.xml"));
InputStream in = new FileInputStream(tempDocxXmlPath);
while ((len = in.read(buffer)) != -1) {
zipout.write(buffer, 0, len);
}
in.close();
} else {
while ((len = is.read(buffer)) != -1) {
zipout.write(buffer, 0, len);
}
is.close();
}
}
zipout.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (ZipException e) {
e.printStackTrace();
} catch (TemplateException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
生成文档效果如下:


最新评论
哈哈,夸张了
作者好厉害
网飞没问题, 迪士尼+有解决方案么?
pp助手是安卓手机用的,根本下载用不来苹果
已解决
这样的话数据库里的结构为{"attachment":{"content":"xxx"}}, 要怎么才能变成{"content":"xxx"},从而使结构保持一致?
赞! make test不过的坑都写到的,谢谢楼主~
谢谢你