
语法:
ROW_NUMBER() OVER(PARTITION BY COLUMN ORDER BY COLUMN)
简单的说row_number()从1开始,为每一条分组记录返回一个数字,这里的ROW_NUMBER() OVER (ORDER BY xlh DESC) 是先把xlh列降序,再为降序以后的没条xlh记录返回一个序号。
示例:
| xlh | row_num |
|---|---|
| 1700 | 1 |
| 1500 | 2 |
| 1085 | 3 |
| 710 | 4 |
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)。
示例:
初始化数据:
create table employee (empid number(9) ,deptid number(9) ,salary decimal(10,2));
insert into employee values (1, 10, 5500.00);
insert into employee values (2, 10, 4500.00);
insert into employee values (3, 20, 1900.00);
insert into employee values (4, 20, 4800.00);
insert into employee values (5, 40, 6500.00);
insert into employee values (6, 40, 14500.00);
insert into employee values (7, 40, 44500.00);
insert into employee values (8, 50, 6500.00);
insert into employee values (9, 50, 7500.00);
数据显示为:
| empid | deptid | salary |
|---|---|---|
| 1 | 10 | 5500.00 |
| 2 | 10 | 4500.00 |
| 3 | 20 | 1900.00 |
| 4 | 20 | 4800.00 |
| 5 | 40 | 6500.00 |
| 6 | 40 | 14500.00 |
| 7 | 40 | 44500.00 |
| 8 | 50 | 6500.00 |
| 9 | 50 | 7500.00 |
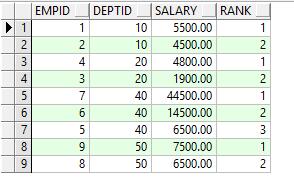
需求:根据部门分组,显示每个部门的工资等级
预期结果:
| empid | deptid | salary | rank |
|---|---|---|---|
| 1 | 10 | 5500.00 | 1 |
| 2 | 10 | 4500.00 | 2 |
| 4 | 20 | 4800.00 | 1 |
| 3 | 20 | 1900.00 | 2 |
| 7 | 40 | 44500.00 | 1 |
| 6 | 40 | 14500.00 | 2 |
| 5 | 40 | 6500.00 | 3 |
| 9 | 50 | 7500.00 | 1 |
| 8 | 50 | 6500.00 | 2 |
SQL脚本:
select e.*,
Row_Number() OVER(partition by deptid ORDER BY salary desc) rank
FROM employee e;
执行结果如下图:


最新评论
哈哈,夸张了
作者好厉害
网飞没问题, 迪士尼+有解决方案么?
pp助手是安卓手机用的,根本下载用不来苹果
已解决
这样的话数据库里的结构为{"attachment":{"content":"xxx"}}, 要怎么才能变成{"content":"xxx"},从而使结构保持一致?
赞! make test不过的坑都写到的,谢谢楼主~
谢谢你