
环境搭建
由于平时开发工作主要在windows平台进行,所以在Windows平台搭建spark开发环境很有必要,在开始进行程序开发之前你可能需要参考以下文章:
假定以上环境你都搭建好了,那么进行接下来的工作。
运行程序
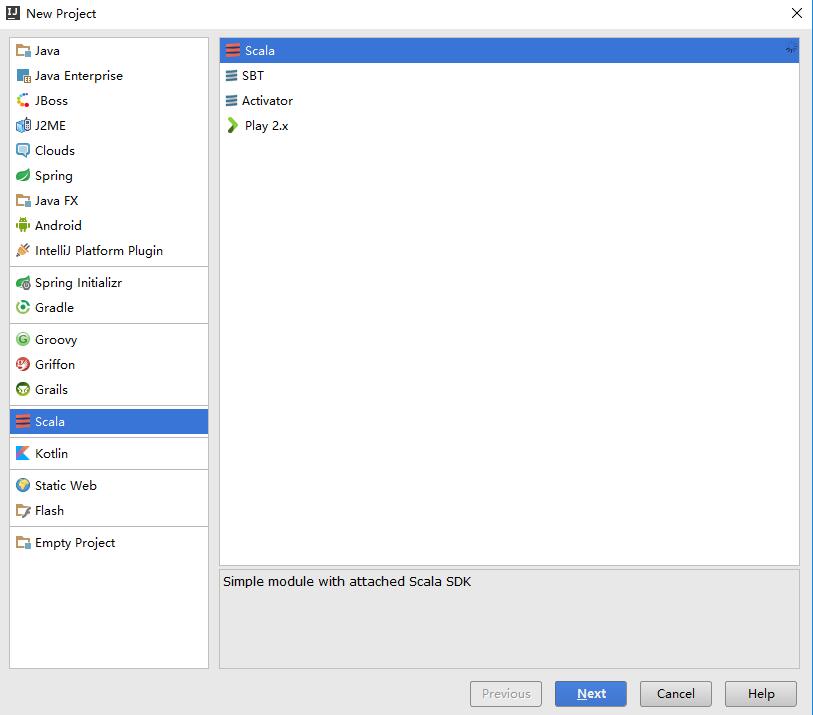
1.首先运行Idea程序,点击File –>New –>Project新建一个Scala工程,如下图;
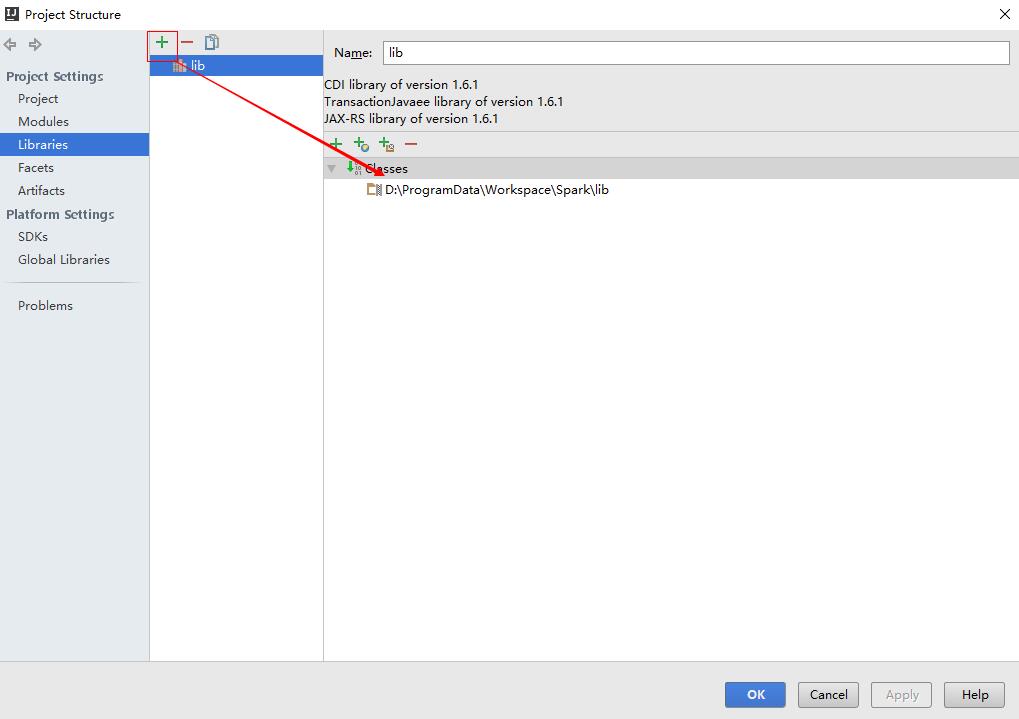
2.在工程根目录下,新建一个目录lib,用来引入需要的jar文件,然后在File –> Project Structure –>Libraries中把目录添加进去,如下图:
3.在你下载的spark-1.6.1-bin-hadoop2.6中的lib目录找到spark-assembly-1.6.1-hadoop2.6.0.jar,并把它放到lib目录下;

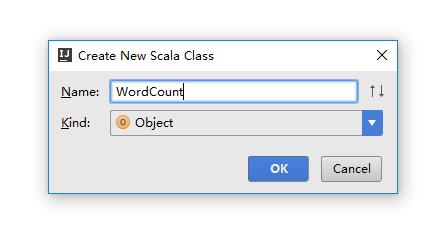
4.新建一个Scala Object,如下图;
5.写入以下代码
package spark
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by iwwenbo on 2016/4/29.
*/
object WordCount {
def main(args: Array[String]) {
//这里spark是单机模式,所以master为local
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
val line = sc.textFile("hdfs://localhost:9000/user/input/wordcount.txt")
line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect().foreach(println)
sc.stop()
}
}
6.新建一个wordcount.txt文件,把它输入到hdfs中,常用的hadoop shell命令参考这里;
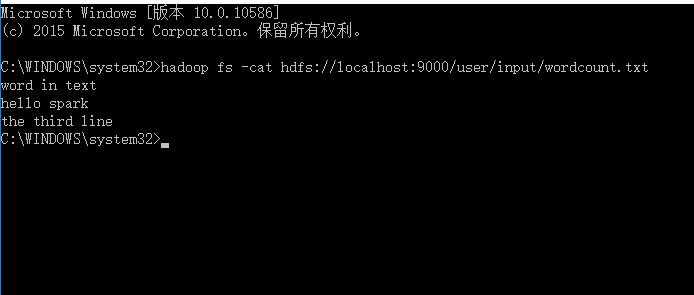
7.运行程序,输出如下:
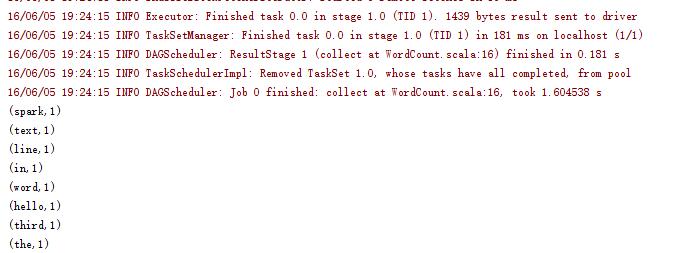
补充:上述示例的代码文件请到Github下载参考;


最新评论
哈哈,夸张了
作者好厉害
网飞没问题, 迪士尼+有解决方案么?
pp助手是安卓手机用的,根本下载用不来苹果
已解决
这样的话数据库里的结构为{"attachment":{"content":"xxx"}}, 要怎么才能变成{"content":"xxx"},从而使结构保持一致?
赞! make test不过的坑都写到的,谢谢楼主~
谢谢你